



I hope you enjoy reading this blog post.
If you want to get more traffic, Contact Us


Click Here - Free 30-Minute Strategy Session
Be quick! FREE spots are almost gone for this Month. Free Quote

For those of you – marketers and website owners – wanting to make it big online, did you know that making it to the top of the Search Engine Results Pages requires you to have unique and informative content and not duplicate content? Yes, after all content is the king.Lets find out more about what is duplicate content and why does it matter.
Duplicate content in SEO is not accepted.

Click Here – Free 30-Minute Strategy Session
Be quick! FREE spots are almost gone for this Month
Search engines have a problem and that is called the “duplicate content” in SEO.
Duplicate content is the content which is displayed on multiple URLs or locations across the web.
Due to this, search engines will often not know which content page should be displayed and which ones should not be in the search results.
This will hugely hurt a web page’s ranking.
So, duplicate content and SEO are directly proportional.
The problem worsens when search users begin linking to every different version of a given web content, making the problem bigger.
In this blog, we have made an effort to answer what is duplicate content, what is considered duplicate content etc.
Let us get started without any further delay.
Google duplicate content in SEO is nothing but the content that appears in over one place on the Internet.
This particular “one place” is referred to as the location having a unique web address or URL.
Therefore, is the same piece of content appears at multiple web addresses, then that will be referred to as duplicate content in SEO.
Although technically it might look like a penalty, the chances are that duplicate content in SEO will hugely impact your search engine rankings.
Besides, there is something called as “appreciably similar” content, as the Google refers to it, which are content that appears at multiple locations across the Internet.
This makes it extremely difficult for the search engines to choose which version can be the most relevant to any given search query.
Hope this answered the question – what is duplicate.
The next question that strikes after what is duplicate content is does duplicate content hurt SEO?
Well, it very much does! Google duplicate content penalty is the proof for this.
Google penalties for duplicate content and duplicate posts.
So, if you want to escape Google duplicate content penalty, you will have to get rid of duplicate content on website.
Now duplicate content presents major threats to both search engines as well as website owners.
Let us see these issues in detail.
Done with what is duplicate content? Now let us move on to the threats that are posed by this.
Duplicate content on different websites will make site owners and marketers suffer their rankings as well as loss in traffic.
These problems often stem out from two major problems:

When it comes to search engines, duplicate content can pose three major threats, those are:
1. They will not know which version should be excluded or included from their indices
2. They will not know whether they should direct link metrics such as the link equity, authority, anchor text, trust etc. to one particular page or just separate it between different versions
3. They will also not be sure of which versions to rank for when it comes to answering the query results
So, what will be the net result? Well, it will be a piece of content which will not get any search visibility that it would otherwise fetch.
In most of the cases, marketers and website owners do not create duplicate content intentionally.
However, it certainly does not mean that it is not present out there.
Furthermore, some of the estimates indicate that close to 29% of web actually comprises of duplicate content.
While we understand that most of times duplicate content is not created intentionally, following are some of the common ways in which it is created:
Some of the URL parameters like certain analytics codes and the tracking are often known to create duplicate content issues.
This is not only a problem that is caused by the parameters, but it can also be something to do with the sequence of those parameters – that is the way in which they appear in the URL.
For instance, let us consider the following URL structures:
Another factor that commonly creates duplicate content is “Session ID”.
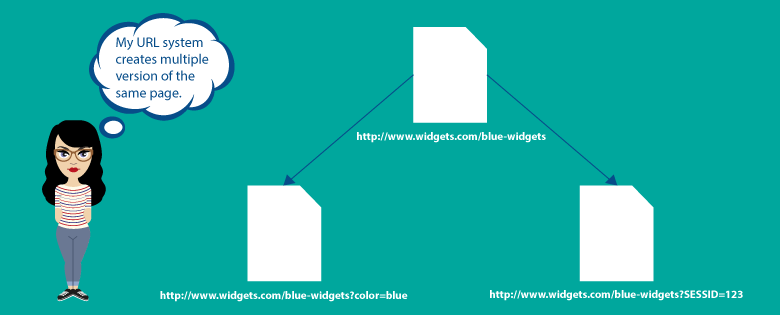
This mainly happens when every user who visits a particular website will be assigned a unique session ID, which then gets stored in the URL.
In addition, the printer friendly versions of the content will also contribute to duplicate content issues, particularly when different versions of a given page get indexed.

So, one point to keep in mind at this point is that whenever possible it will be very beneficial to forego the process of adding any alternate URL versions or more URL parameters.
This is because the information contained within them will often be passed on through the scripts.
If your website contains different versions at “site.com” as well as “www.site.com” (that is with and without the prefix “www”), also that same content can be applied to the sites – both these versions – it simply means that you have created the duplicates of both these pages.
This also applies to the websites that maintain either pf their versions at https:// as well as http://. so, when both the versions of a particular page are live and are also visible to the search engines, then the chances are that you will get into the issues of duplicate content.
When we say content, it not only includes the editorial content or the blog posts, but it also includes the pages on product information.
Scrapers who republish a piece of already published blog content on their website will be an obvious source of duplicate content.
However, there is a problem faced by the e-commerce websites also – identical product information.
If multiple websites sell a particular product or the same items, all these websites will end up using the same manufacturer’s descriptions for those items.
In this way same content will end up in different locations across the web.
Now fixing issues with the Google SEO duplicate content comes down to a single central idea and can also be done using duplicate content tools.
Here, the central idea is to specify which of these duplicates is the one that is “correct”.
Whenever website content is found across different locations in the Internet, it should always be canonicalized for the search engines.
So now, let us look into the three major ways to carry this out. These include:
In majority of the cases, an ideal way would be to combat the duplicate content issue would be to set up 301 redirects from the pages that are “duplicate” to the original pages.
When several pages having the potential to rank well will be combined to one single page they will completely stop competing with each other another and will also develop a stronger popularity and relevancy signals all over.
This will then positively impact the ability of the “actual”/”original” page to rank well.

The next option to deal with the duplicate can be to leverage the rel=canonical.
This will guide the search engines that the particular page should be considered as though it is a copy of the URL that is specified.

Also, it tells that the content metrics, all the links as well as the “ranking power” applied by the search engines to this web page should actually be provided to the URL that is specified.
Rel=canonical attribute is a portion of a web page’s HTML head:
<head>
(different code which could be in the HTML head of your document)
<link href=”ORIGINAL PAGE’s URL” rel=”canonical” />
(different code which could be in the HTML head of your document)
</head>
This attribute should then be added to each and every version of the duplicate page’s HTML head.
This should be done along with the portion “URL of the actual page”, discussed above should be replaced by the link to the actual (canonical) page.
Ensure that the quotation marks are retained.
The attribute roughly provides the equal amount of the ranking power or the link equity as the 301 redirect.
However, as it is implemented at the level of a web page, rather than the server level, it often takes very less time for development as well as to implement.
A meta tag that is specifically useful to deal with the issues associated with the duplicate content is the meta robots.
When it is leveraged with the values such as “nofollow, index”. While this is technically referred to as content=”noindex,follow”, it is commonly known as Meta Noindex,Follow.
You can easily add the meta robots tag to HTML heads of each of the pages which have to be kept out of the search engine’s index.
Now, this meta robots tag enables the search engines to enable the links on the web page but prevents them from adding those links to the indices.
It is essential that this duplicate should also be crawled, although you do not want search engines to index it.
This is because Google hugely cautions against restricting its crawling access to duplicate content that is present on a website.
Search engines always like to be accessible to all the errors that tend to arise within the codes.
This is mainly because it helps them to decide in otherwise ambiguous situations.
Leveraging meta robots can particularly be a great solution for issues associated with the duplicate content related to pagination.
Google search console enables marketers and website owners to set their preferred domain for their websites.
It will also help you to make it clear whether the Googlebot should crawl over different URL parameters in a different way.
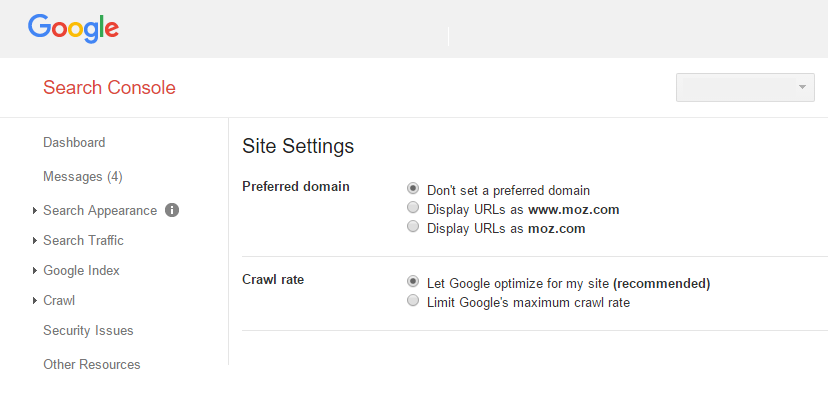
Based on the actual cause of the issues associated with your duplicate content and the structure of your URL – you might get a solution of setting up parameter holding or the preferred domain or both.
When you choose parameter holding as your option to fight duplicate content issues, there might be a problem – the modifications you make will work only for the Google.
Basically, any plan that is implemented using the Google’s search console will certainly not affect the way in which the crawlers of the Bing or any other search engine apart from Google will interpret your website.
So, for other search engines, you can leverage web master tools along with the adjustments to the settings on Google Search console.
Following are some of the tips to deal with the issues created by the duplicate content:
In this way you can safeguard your original content and stay atop of the SERPs.
Be quick! FREE spots are almost gone for this Month



LEAVE A REPLY